An RNN's Adventure With Various Datasets
Can machines learn to read languages that humans read forwards backwards? Even when some languages are created to be written from left to right and top to bottom, will there be any pattern, relation, or such to be found when read reversed?
We, Yanjinlkham and I, experimented with a character-level RNN language model in Tensorflow[1] with regular texts in English and Mongolian for our previous project from which the questions above were left unanswered. Therefore, we run some new experiments to find answers for our questions. Although not knowing what results to expect, we believed that these experiments will help us find our answers somehow.
Training data and code we used are in this repository: https://github.com/graphitics/reversed
Data
We decided to use previous project datasets to be reversed and then used as training datasets for this experiment.
-
English dataset: Various works of Shakespeare, 5.3 MB
-
Mongolian dataset: Laws of Mongolia, 22.5 MB
We defined reversing texts as shown below.
Original text:
“Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.”
Reversed text:
“.murobal tse di mina tillom tnuresed aiciffo iuq apluc ni tnus ,tnediorp non tatadipuc taceacco tnis ruetpecxE .rutairap allun taiguf ue erolod mullic esse tilev etatpulov ni tiredneherper ni rolod eruri etua siuD .tauqesnoc odommoc ae xe piuqila tu isin sirobal ocmallu noitaticrexe durtson siuq ,mainev minim da mine tU .auqila angam erolod te erobal tu tnudidicni ropmet domsuie od des ,tile gnicsipida rutetcesnoc ,tema tis rolod muspi meroL”
RNN model
Bearing intention to make clear and understandable comparisons with the previous results, we used the same language model as before. With our reversed datasets, we hoped to understand what the model is really learning.
Results
1. Following are statistics and snapshots of training processes on English dataset.
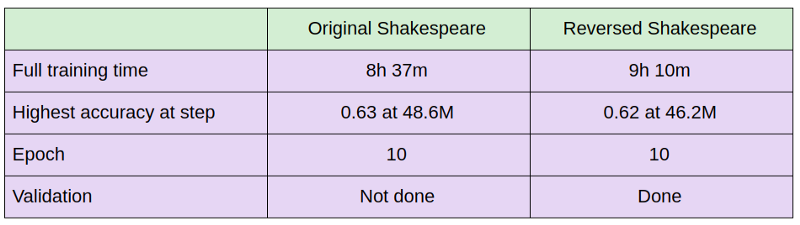 Table 1: Comparison of training process between original and reversed Shakespeare data
Table 1: Comparison of training process between original and reversed Shakespeare data
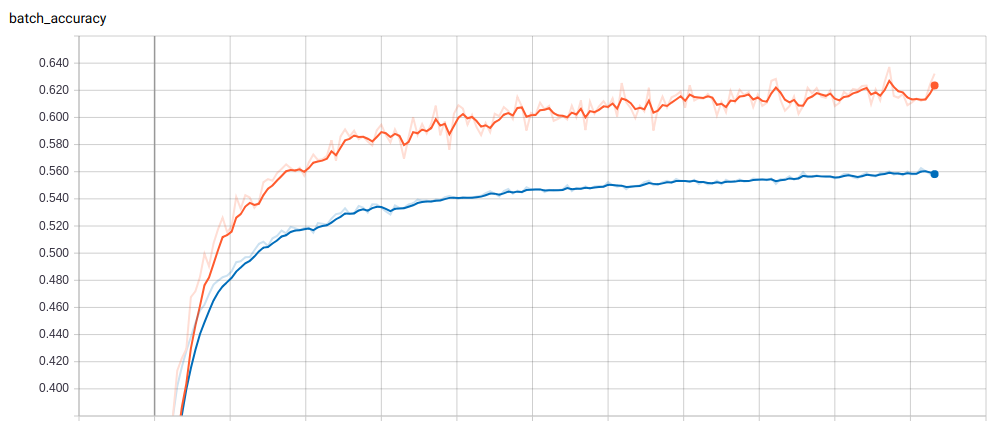 Image 1. Tensorboard log of the training and validation accuracy of the original Shakespeare data
Image 1. Tensorboard log of the training and validation accuracy of the original Shakespeare data
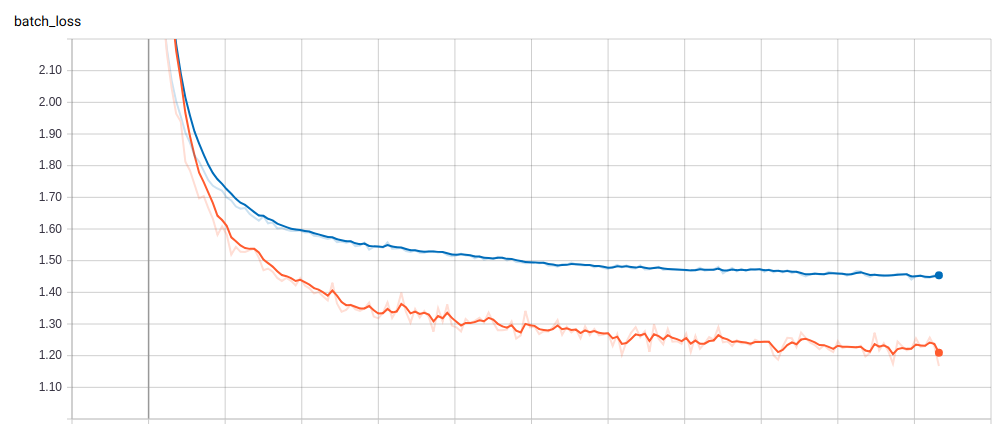 Image 2. Tensorboard log of the training and validation loss of the original Shakespeare data
Image 2. Tensorboard log of the training and validation loss of the original Shakespeare data
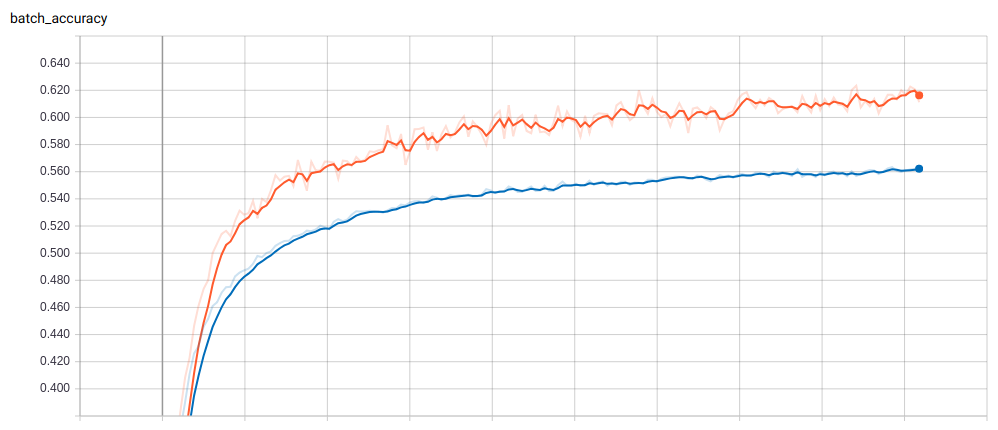 Image 3. Tensorboard log of the training and validation accuracy of the reversed Shakespeare data
Image 3. Tensorboard log of the training and validation accuracy of the reversed Shakespeare data
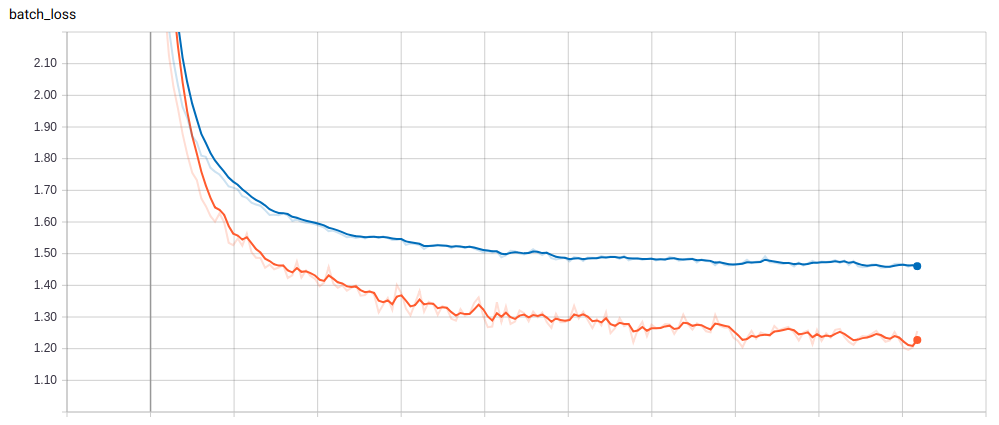 Image 4. Tensorboard log of the training and validation loss of the reversed Shakespeare data
Image 4. Tensorboard log of the training and validation loss of the reversed Shakespeare data
Generated text by trained model fed with reversed Shakespeare data:
.ecarg ruoy ekat ,em tsniaga erac oS ,em erussa ew taht esoht fo tsaef eht no tuo dna ,seye enim fo secnaretnoc eht ni erutan ym ekat ,em evael ,eehtirp I ,em ot ti ekat ,em tsniaga ton sita :emoc ew ereh ,yaN ORDEP NOD .em evig ,em evig uoy fi ,yA AILIME ?em evah uoy lliw ,tahW .em evael uoy fi ,eerht yB OISSEC .ti fo em tsevael uoht ,erom oN OGAI .ti ekat I sa ,yaN OISSAC .seirevil ruoy esaelp tsum I ,ecneicserc ym ,emoc ,yaN AIVILO .em htiw era uoy taht ,yaN OISSAC ?em htiw kaeps ot ton eb ereht sI OITNECNIV EKUD
Reversion (note that this hasn’t been resulted by original Shakespeare training) of the generated text above:
DUKE VINCENTIO Is there be not to speak with me? CASSIO Nay, that you are with me. OLIVIA Nay, come, my crescience, I must please your liveries. CASSIO Nay, as I take it. IAGO No more, thou leavest me of it. CESSIO By three, if you leave me. What, will you have me? EMILIA Ay, if you give me, give me. DON PEDRO Nay, here we come: atis not against me, take it to me, I prithee, leave me, take my nature in the conterances of mine eyes, and out on the feast of those that we assure me, So care against me, take your grace.
2. Following are the statistics and snapshots of training processes on Mongolian dataset.
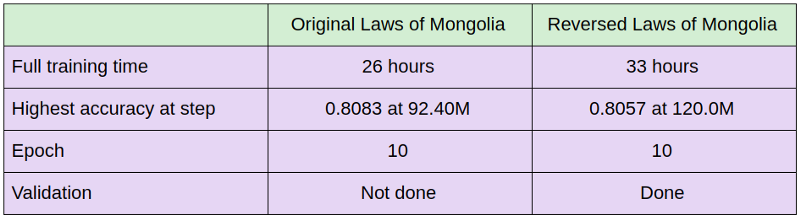 Table 2: Comparison of training process between original and reversed Laws of Mongolia data
Table 2: Comparison of training process between original and reversed Laws of Mongolia data
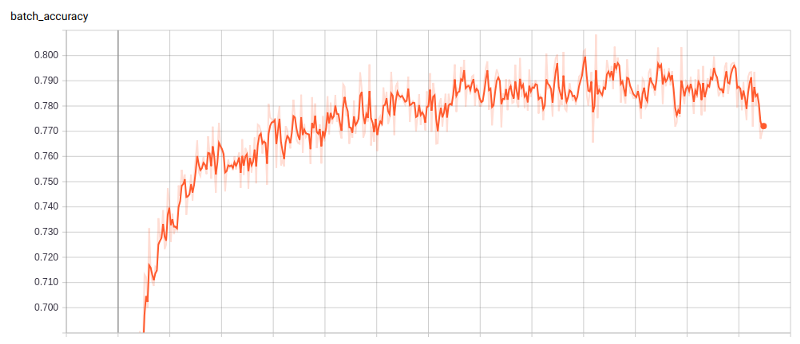 Image 5. Tensorboard log of the training accuracy of the original Laws of Mongolia data
Image 5. Tensorboard log of the training accuracy of the original Laws of Mongolia data
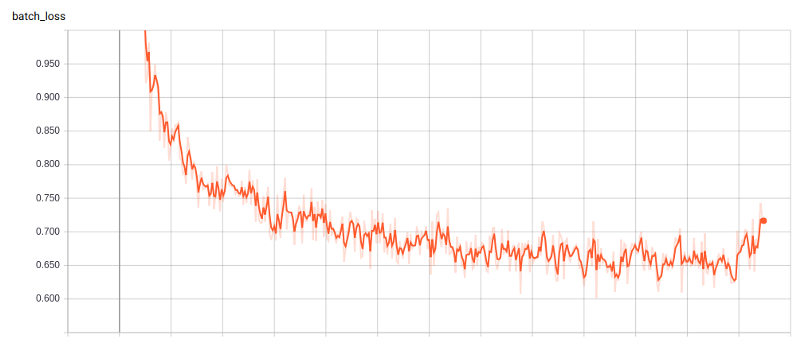 Image 6. Tensorboard log of the training loss of the original Laws of Mongolia data
Image 6. Tensorboard log of the training loss of the original Laws of Mongolia data
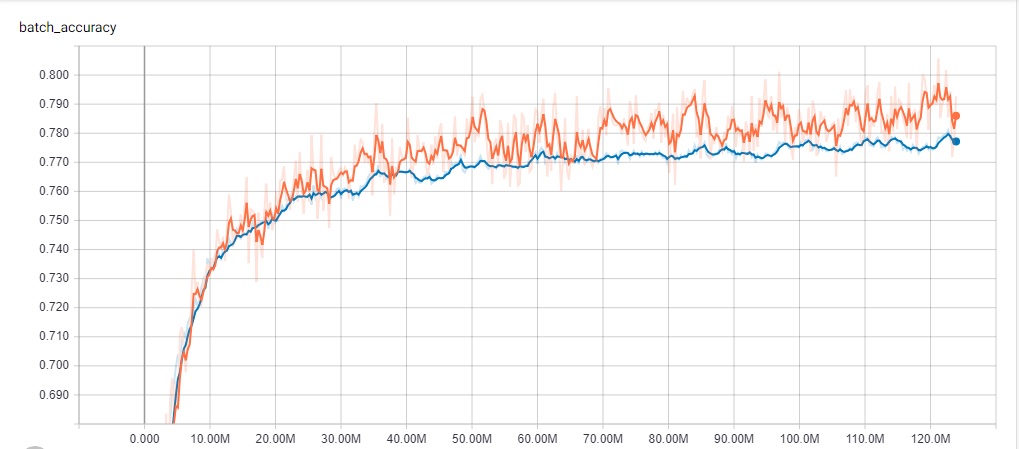 Image 7. Tensorboard log of the training and validation accuracy of the reversed Laws of Mongolia data
Image 7. Tensorboard log of the training and validation accuracy of the reversed Laws of Mongolia data
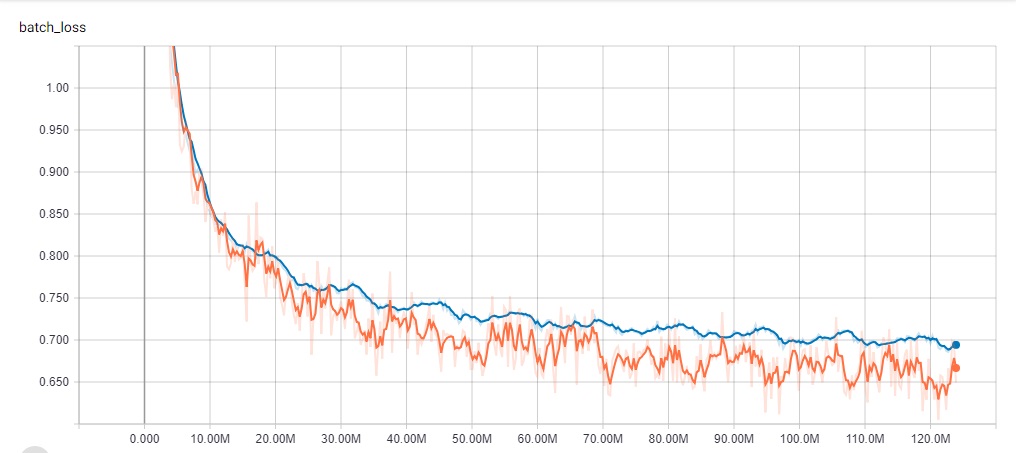 Image 8. Tensorboard log of the training and validation loss of the reversed Laws of Mongolia data
Image 8. Tensorboard log of the training and validation loss of the reversed Laws of Mongolia data
Generated text by trained model fed with reversed Laws of Mongolia data:
;халууро днаагаллижа лйү хэгтэцйүг рээгчиб ,хэлүүзү гэлжмэд дахалуурсволоб гыголдоб нйирөт ,хагнах рээллээдэм нйикитситатс йинсэднү.1.1.91 :анйаб йэтгэрүү гич хаарад агаллуугйаб ынаагрихаз нйирөт нэслэхрэ ладууса нйивсөТ.1.91 хрэ нэрүб ныград ныгаллуугйаб ынаагрихаз нйирөт нэслэхрэ ладууса нйивсөт ,үүхнаС .лйүз раагуд 5 .оноотгот раилуух гымруж хэлүүжгэрэх гйижмоотгот ьлуух йахут нйилрөөшвөз йагсут нйахут налуужмад рээлэлсэднү насааз д-1.4 нйилуух энЭ.3.61 .энэлгэрэх гйигрүү халуурсволоб ланас нйилөлвөз хадриду нөлөөлөт нолоб нйигнас нйо ныслУ логноМ ьн тлироз нйилуух энЭ тлироз нйилууХ.лйүз рээгүд 1 ЛЭЛСЭДНҮ ГЭЛТЙИН ГЭЛҮБ РЭЭГҮДГЭН ЙАХУТ НЫЛДЙАБ НЙҮЗ хРЭ НЙИЧГЭЛЙИХРЭРҮ ГЭЛҮБ РААГУДВАТ
Reversion (note that this hasn’t been resulted by original Laws of Mongolia training) of the generated text above:
ТАВДУГААР БҮЛЭГ ҮРЭРХИЙЛЭГЧИЙН ЭРх ЗҮЙН БАЙДЛЫН ТУХАЙ НЭГДҮГЭЭР БҮЛЭГ НИЙТЛЭГ ҮНДЭСЛЭЛ 1 дүгээр зүйл.Хуулийн зорилт Энэ хуулийн зорилт нь Монгол Улсын ойн сангийн болон төлөөлөн удирдах зөвлөлийн санал боловсруулах үүргийг хэрэглэнэ. 16.3.Энэ хуулийн 4.1-д заасан үндэслэлээр дамжуулан тухайн тусгай зөвшөөрлийн тухай хууль тогтоомжийг хэрэгжүүлэх журмыг хуулиар тогтооно. 5 дугаар зүйл. Санхүү, төсвийн асуудал эрхэлсэн төрийн захиргааны байгууллагын даргын бүрэн эрх 19.1.Төсвийн асуудал эрхэлсэн төрийн захиргааны байгууллага дараах чиг үүрэгтэй байна: 19.1.1.үндэсний статистикийн мэдээллээр хангах, төрийн бодлогыг боловсруулахад дэмжлэг үзүүлэх, бичгээр гүйцэтгэх үйл ажиллагаанд оруулах;
P.S.: The text above makes sense just as the generated text shown in our previous project results here.
Conclusion
Learnings — While conducting our small experiments, we learned about more types of language models and text data transformation methods. As for language models, we learned that there were statistical models before neural network based language models. As for neural language models, we learned that there could be different structures for different approaches such as character-level, word-level language models and word representations. On the other hand, data transformation including reversion can be of various types. For example, depending on the writing system of a language, one can reverse texts from left-to-right or right-to-left or even top-to-bottom.
Answers to the questions and what to do next— Let us briefly remind you what questions we had set in front of us before we started our experiments.
Can machines learn to read languages that humans read forwards backwards? Even when some languages are created to be written from left to right and top to bottom, will there be any pattern, relation, or such to be found when read reversed?
We thought hard and long about our questions to realize that our core question really was “What language element is this model learning?”. After getting first of our results, we also realized that we couldn’t determine what exact language element the model is learning or is not learning with this small set of experiments.
We reasoned that if our char-level model learns language elements caused by the language’s directional sequential nature, the model can not learn as well when fed with transformed (directional sequential property, if it exists, differed) dataset. Since the model we trained learned original and reversed texts at same rate, we began questioning where our experiments went wrong. We are questioning:
-
our choice of data transformation for this model — since the language model we trained is character-level, using this version of reversion was not to break directional sequential property (if it is there to begin with);
-
existence of any directional sequential property in the texts;
-
our initial hypothesis which the model learns specific language elements derived from its directional sequential property.
Now, we are planning to rule out our possible mistakes by:
-
choosing different data transformation for this model as well as choosing different language model for this transformation; and then, more experiments;
-
training on languages that have different writing systems.
References
[1] https://github.com/martin-gorner/tensorflow-rnn-shakespeare
[2] https://karpathy.github.io/2015/05/21/rnn-effectiveness/
[3] Fei-Fei Li & Justin Johnson & Serena Yeung’s Lecture 10 slides on Recurrent Neural Networks
This piece was co-written with Yanjinlkham.